


Snowflake Deep Dive
Figuring out Snowflake's value proposition and valuation

Disclosure: As of the time of writing, I do not own a position in Snowflake. I may make trades in this stock in the future and my work here should not be taken as financial advice but rather for informational purposes.
Snowflake’s Story & Company Overview
Snowflake's inception and expansion were methodically planned and fueled by venture capitalists right from its beginning. Mike Speiser of Sutter Hill Ventures was the initial backer, fostering the concept within their premises and gathering founders with profound expertise to establish the company.
One of the founding members, Dageville, came on board after leaving Oracle, dissatisfied with its hesitant move towards cloud computing, aiming to develop a product free from the limitations of initial investments and restricted bandwidth.
Between 2014 and 2019, Snowflake focused on offering a cloud data warehouse, marketing its analytical database. This approach took a new direction with the arrival of Slootman in 2019, leading to a rebranding of its business model to Cloud Data Platform in 2019 and later to Data Cloud in 2020.

Snowflake was the first company to deliver a cloud-native enterprise database that centralizes all company data into one location. The strategy was designed to establish Snowflake as an essential middleware layer within the data ecosystem, effectively making it a levy on data expansion. Snowflake's plan involves utilizing its user-friendly analytical database to transition a significant portion of the Global 2000's on-premise databases.
However, the long-term goal for Snowflake is to emerge as the premier repository and processing hub for global data within the data infrastructure. To achieve this indispensable status, Snowflake is cultivating an ecosystem conducive to third-party data sharing and monetization of their data or applications. Additionally, it aims to expand its utility across various use cases, enabling any programming language, data type, or application to tap into Snowflake’s platform for monetization purposes over time.

Value Proposition
Snowflake significantly eases the process of managing data with its user-friendly and straightforward implementation. Unlike previous solutions that demanded substantial initial investments and extensive, ongoing management, Snowflake’s fully managed turnkey solution handles data upkeep and optimizes performance for its users.
The platform is known for its speed, utilizing cloud resources efficiently. It allows for the infinite cloning of data without changing the original format and supports simultaneous access by an unlimited number of users without compromising performance. This on-demand computing model helps customers avoid hefty initial costs. For instance, Western Union reported a 50% reduction in data warehousing expenses. Other companies such as Capital One, Deliveroo, and JetBlue, have publicly shared their positive outcomes after migrating to the cloud.
Compared to Databricks, which often requires a dedicated team of engineers for implementation and management, Snowflake stands out for its simplicity and ease of use, overcoming common pitfalls of prior solutions, including the challenges associated with on-premise systems.
One of Snowflake's technical strengths is its capability to execute numerous calculations at once by breaking down large tasks into smaller segments for processing. This approach allows customers to achieve results much faster than with older technologies (e.g., 20 seconds with Snowflake vs. 20 minutes with traditional methods).
Network Effect
Snowflake has been looking to create a network effect around its platform to enable companies to share their data with partnering companies in their supply chains.
The CFO previously mentioned: “Data sharing is a key differentiator for Snowflake, that is a great lead generator for us. And we really see that taking off in financial services, we're seeing a lot of our customers who are telling their data suppliers that they want them on Snowflake. It's a huge network effect. And a lot of people talk about data sharing, but we're really the only ones who do it where the data actually never moves, the custodian of that data always retains that data.”
Product Overview
Snowflake is utilized for analytical tasks such as forecasting, budgeting, and reporting, primarily by business analysts tracking KPIs like sales or future demand predictions. It functions similarly to an expansive spreadsheet capable of executing limitless pivot tables and macros rapidly, with the added advantage of simultaneous access by numerous users. This "spreadsheet" can store both structured data, such as numerical values, and unstructured data, including emails, zip files, web pages, and social media content. Even with its capacity to house unstructured data, Snowflake organizes it efficiently into a unique proprietary format, enhancing read speeds. It further divides calculations into tiny segments, boosting response times, all accessible via SQL.
A significant advancement in Snowflake’s technology has been the facilitation of secure data sharing between different organizations. Its contemporary cloud data platform permits the real-time, regulated exchange of data across various clouds and regions without the need to physically move files or generate redundant copies.
Previously, sharing data typically required transmitting files through the internet, a process that was not only hard to automate but also lacked security, as third parties would gain possession of the data. In contrast, Snowflake's approach to data sharing is not only secure but also easily accessible to individuals without technical expertise or coding knowledge.

A superset of shared data can be created without making any copies and on a temporary basis.

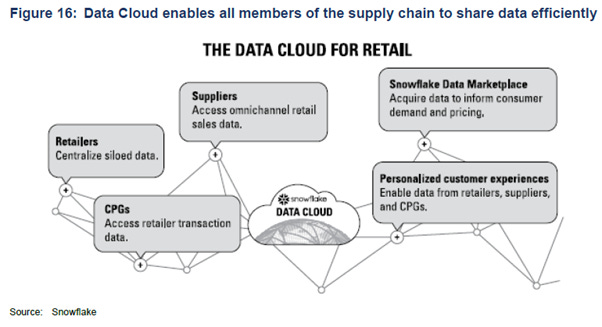
The Data Cloud builds upon the concept of the Cloud Data Platform, encompassing all stakeholders. It forms a global network where thousands of organizations utilize data with the advantages of cloud scalability, concurrent access, and high performance. Within the Data Cloud, organizations can consolidate their fragmented data, enabling them to find and share data, as well as carry out various analytic tasks.
Similar to the internet, the Data Cloud allows any participant to connect, manage, and leverage their data while also linking to a broader data ecosystem. This includes the ability to access third-party data and data services available through the Snowflake Data Marketplace.

Data Cloud facilitates participation in the ecosystem rather than competing just on the feature set for each individual instance. Snowflake only benefits from compute that customers use incrementally, and will not monetise the ecosystem by taking a cut from 3rd party revenues.
The elements that should create a network effect are:
1. Data Marketplace:
Independent data providers market their enriched data sets to the ecosystem participants. Snowflake Data Marketplace listings has more than 1,100 data listings from over 230 providers as of Mar 2022.
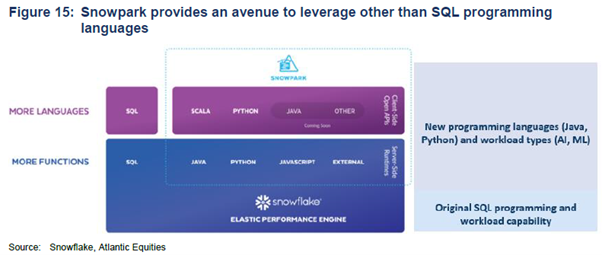
2. Snowpark
Provides programming language choice to the Data Cloud and a runtime environment for data cleansing, analysis and AI functions. It enables the expansion of work types by leveraging other than SQL programming languages like Python, Scala, Java or Spark. Data sharing creates customer stickiness and high switching costs. The more users on the system, the harder it becomes to switch. Sharing is free for customers, and Snowflake benefits from increased compute in its query processing layer.
Real-life Data Cloud situations in data sharing:
1. In retail, grocers can share live inventory data with CPG companies.
2. Health care providers can share patients’ health data securely with partners.
3. Media firms can share subscriber data with advertisers and online ad platforms.
4. Manufacturers can synchronise supply chain activities.
These use cases were previously difficult to deliver on. They had to be custom-built, expensive to develop, hard to administer, hard to protect and inflexible. By unified data sharing under one proprietary system, Snowflake unlocked the next step of data expansion.
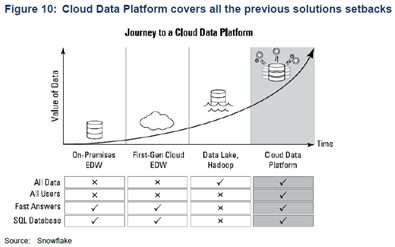
Cloud Data Platform
The move to Cloud Data Platform granted Snowflake’s customers access to unstructured data, secure data sharing between enterprises and introduced more programming languages like Python. This saw TAM expansion from $14b to at least $90b.
Cloud data platform is a one-stop shop for all data needs. Simplicity is crucial. Many organisations have established unique solutions for each type of data and each type of workload:
1. A data lake to explore raw and semi-structured data as a prelude to data science initiatives.
2. A data warehouse for SQL-based operational reporting.
3. An object storage system to manage unstructured video and image data
The emergence of cloud warehouses enable all data structures to merge under one roof.
Advantages: Simplifies infrastructure by creating a single place for many types of data and data workload. Broadens the range of data processing and analytics workloads like AI and ML. Reduces the number of stages the data needs to move through before it becomes actionable. Efficiently governs the data, on-demand.
Snowflake Cortex
Cortex introduces the ability to query data within Snowflake using natural language, eliminating the need for SQL knowledge. This development makes the platform more accessible to a broader range of users, such as sales teams, HR professionals, and managers, allowing them to directly utilize Snowflake without the intermediary step of consulting a business analyst for data retrieval. Additionally, Snowflake is rolling out Co-Pilot, a feature designed to lower entry barriers, enabling users to quickly become proficient and productive with the platform.
Cortex enhances the platform with Large Language Model (LLM) capabilities. Utilizing PDF documents stored in Snowflake's data lake, Cortex leverages these documents to generate an LLM tailored to a company's specific expertise. Moreover, Snowflake plans to host LLM models from Mistral and Meta, providing customers with the tools to customize these models using their data.
Unistore
Unistore transforms Snowflake's data warehouse into a fully-fledged database, specifically fine-tuned for traditional row-based database operations like reading, writing, updating, and deleting. It also ensures ACID compliance, positioning Snowflake as a formidable rival to established SQL databases from giants like Oracle, Microsoft, and IBM, but with the added benefit of limitless scalability.
Similar to Snowflake's initiative, Google offers a product named Spanner, representing the domain known as 'NewSQL.' This sector is characterized by SQL databases capable of horizontal scaling. Oracle, known for its hyper-speed performances with latencies below one millisecond thanks to its C-based software running on a single server, has an edge in speed. Snowflake's NewSQL database, however, operates within cloud data centers, encountering network latencies around 10 milliseconds. Nonetheless, for the majority of applications, this 10-millisecond delay is perfectly acceptable.
Sales Strategy
Snowflake has changed the incentive structure of their sales force with the expectation that this is going to accelerate revenue growth. Compensation is now linked with customers’ platform consumption as opposed to bookings. Sales reps previously would sell a one-year deal and give customers unlimited rollover.
The new comp plan comprises of 35% of reps, landing new customers. 55% of the reps are on revenue where their job is to be at the customer, walking the halls, finding new workloads to drive more revenue. And 10% are hybrid, that have a mix of new customers and some small number of existing customers.
Management
Ramaswamy joined the company via the Neeva acquisition last year, a startup focused on applying AI to web search and a field which Ramaswamy previously already was active in at Google. At the latter giant, he ran the search ads business and successfully scaled it to above $100 billion in revenues. And after joining Snowflake, he took control of the company’s AI strategy. Ramaswamy supposedly had other CEO opportunities but chose Snowflake because he believes it stands out in terms of technology and can be a $100 billion revenue company.
Industry Overview
Industry History
Previously, database solutions were cumbersome to use and maintain, with data preparation consuming up to 80% of a data scientist's workload. Altering database structures or integrating different data sources necessitated extensive manual scripting. These older systems often stored data in various locations, creating silos and increasing latency.
Traditional data warehouses were situated on-premises, relying on a company's own servers and hardware, which was costly. Companies bore the expense of hardware acquisition, setup, and continuous management.
While SQL-based systems were adept at managing complex queries and maintaining consistency, they lacked scalability. As a business expanded and data volumes grew, the only solution was to upgrade to larger servers with more memory and CPUs, a strategy that became impractical with the data surge accompanying the internet's growth.
The shift towards horizontal scaling addressed this limitation, distributing data across multiple servers. NoSQL databases like MongoDB, Cassandra, and AWS DynamoDB offered this scalability but struggled with complex queries. Simple queries were manageable, but anything more sophisticated posed challenges.
Data warehouses bridged this gap by funneling data from databases into a warehouse environment for analytics, subsequently visualizing this data on dashboards for managerial insight. Historically, these warehouses used SQL on large servers, separating the workload from primary servers to improve efficiency.
The advent of horizontal scaling in data warehousing led to three generations of solutions over two decades:
1st Gen: Hadoop facilitated horizontal scaling in on-premise data centers but was complex to manage.
2nd Gen: AWS Redshift offered a more user-friendly solution on AWS, though its architecture, which coupled compute and storage, became inefficient as data grew.
3rd Gen: Snowflake revolutionized the approach by decoupling storage and compute, utilizing affordable cloud object storage for data and activating compute resources only as needed. This model prevented unnecessary expenditure on unused computational power.
Snowflake addressed earlier inefficiencies by centralizing data storage, automatically reformatting data into an optimized proprietary file format, and ensuring SQL, the most popular programming language, could access any data.
By storing data separately from where computation occurs, Snowflake's architecture allows for significant cost savings and operational flexibility. Customers pay only for the resources they use, can adjust data warehouse sizes in real-time, and easily share data to prevent silos. Designed for cross-cloud operation, Snowflake also avoids vendor lock-in, addressing a common drawback of on-premises solutions.
Industry Trend
The 2020 Global Data Sphere report by IDC indicates that around 80% of newly generated data is either semi-structured or unstructured, presenting a challenge that traditional databases, whether on-premises or cloud-based, weren't built to tackle. This diversity and volume of data, which often requires processing through various programming languages, complicate both the architecture of databases and the experience for users. Snowflake has responded to this challenge by developing a specialized technology that enables efficient, high-performance analytics on unstructured data using SQL, streamlining access and analysis of this data type.

Snowflake has made it known that their platform is not just a substitute for on-premise solutions like Teradata and Hadoop but is also replacing traditional SQL data warehousing systems from Oracle, Microsoft, and IBM, as well as first-generation cloud data warehouses like AWS Redshift.
Regarding customer optimizations, the CFO stated, “We returned to a normal level of customer optimizations, with 8 out of our top 10 accounts showing sequential growth. Our experience has demonstrated that optimizations enhance our long-term potential.” Optimizations refer to the process of making the compute processes on the platform more efficient, either by Snowflake or the customers themselves, which in turn reduces costs. An example of this is a client improving data indexing, which speeds up query execution. Snowflake's philosophy is that by lowering costs for customers, they encourage the migration of more data and workflows to their platform, thus expanding their market potential.
The CFO highlighted that workload costs have been reduced by half, noting, “We witnessed a 62% rise in the volume of jobs executed on Snowflake on a year-over-year basis, accompanied by a 33% revenue increase. This is because we consistently demonstrate to our customers that our services are becoming increasingly cost-effective for them each year. By doing so, we unlock new opportunities for workloads, and we intend to keep this momentum.”
Intel's CEO, formerly at the helm of virtualization software company VMware, observed, “We are 20 years into the public cloud era, with over 60% of computing now in the cloud, yet more than 80% of data remains on-premises.”
Industry Value Chain
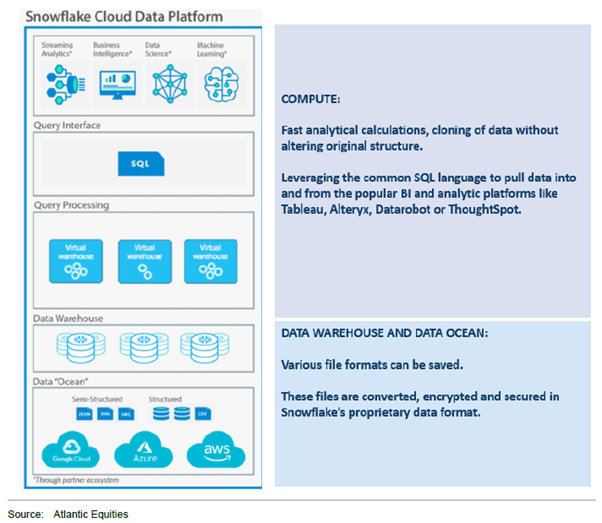
Snowflake aggregates data from various business sources into a single centralized storage repository. Analytical processing is performed in a separate compute layer, for which customers are billed separately. Operating its databases on the infrastructure of the three major cloud providers, Snowflake leases storage and computational resources to its clients. Customers are provided with a virtual private cloud managed within Snowflake's proprietary service environment.
A significant portion of Snowflake's customer base uses AWS for running Snowflake, with the rest predominantly utilizing Azure, and a smaller fraction employing Google Cloud.


Storage: Snowflake continuously stores data on behalf of customers, and this space sits in hyperscalers’ clouds.
Query processing: Compute takes place here. It is a temporary, paid per-second fast computing service
Cloud service: Run by Snowflake. Governs the data transfer, optimization, access and encryption between storage and compute.
Types of data:
Structured data (Customer names, dates, order history, product information): This data type is generally maintained in a neat, predictable, and orderly form, such as a spreadsheet.
Semi-structured data (Web data, CSV files, XML). These data types don’t conform to traditional structured data standards but contain tags or other types of markup that identify individual, distinct entities within the data.
Unstructured data (Audio, video, images, PDFs, and other documents) doesn’t conform to a predefined data model or is not organized in a predefined manner.
Businesses can no longer achieve satisfiable data analytics with structured data (like past sales or clients’ addresses). Instead, various data types including video and social media posts and analyse them on an almost real-time basis and in much larger quantities.

Data can be stored in either Data Warehouse or Data Lake.
Data warehouse: Data warehouse is an analytics database and central repository for data that has already been structured and filtered. The main users are data analysts who have a vast knowledge of SQL. Warehouse data is optimized and transformed so that it can be accessed quickly. Data within the warehouse is queried and analysed to derive insights and build reports and dashboards to drive business outcomes.
Collects only structured and semi-structured data, data is organized and immediately actionable, and used for historical analysis (sales per region).
Data lake: Data lake is similar to a data warehouse in that it collects and stores data. However, data lakes are designed to handle Big data or large amounts of raw data, unstructured data, or semi-structured data. Data lakes typically house much larger quantities of data compared to a warehouse and address more use cases. Given that data lakes consist of unprocessed raw data, a data scientist with specialized expertise is typically needed to manipulate and translate the data.
Collects any data in original, raw format (unstructured data like video), needs to be transformed to be actionable, and often used for predictive analytics (AI/ML).
Note: Snowflake was founded as a Data Warehouse business, but it expanded into Data Lake category over time to capture the AI and Machine Learning opportunity.
Financials
Revenues has risen sharply, driven by compute and storage demand. The company however is guiding only 22% growth for FY25, though many suspect management is being overly conservative due to the CEO change.
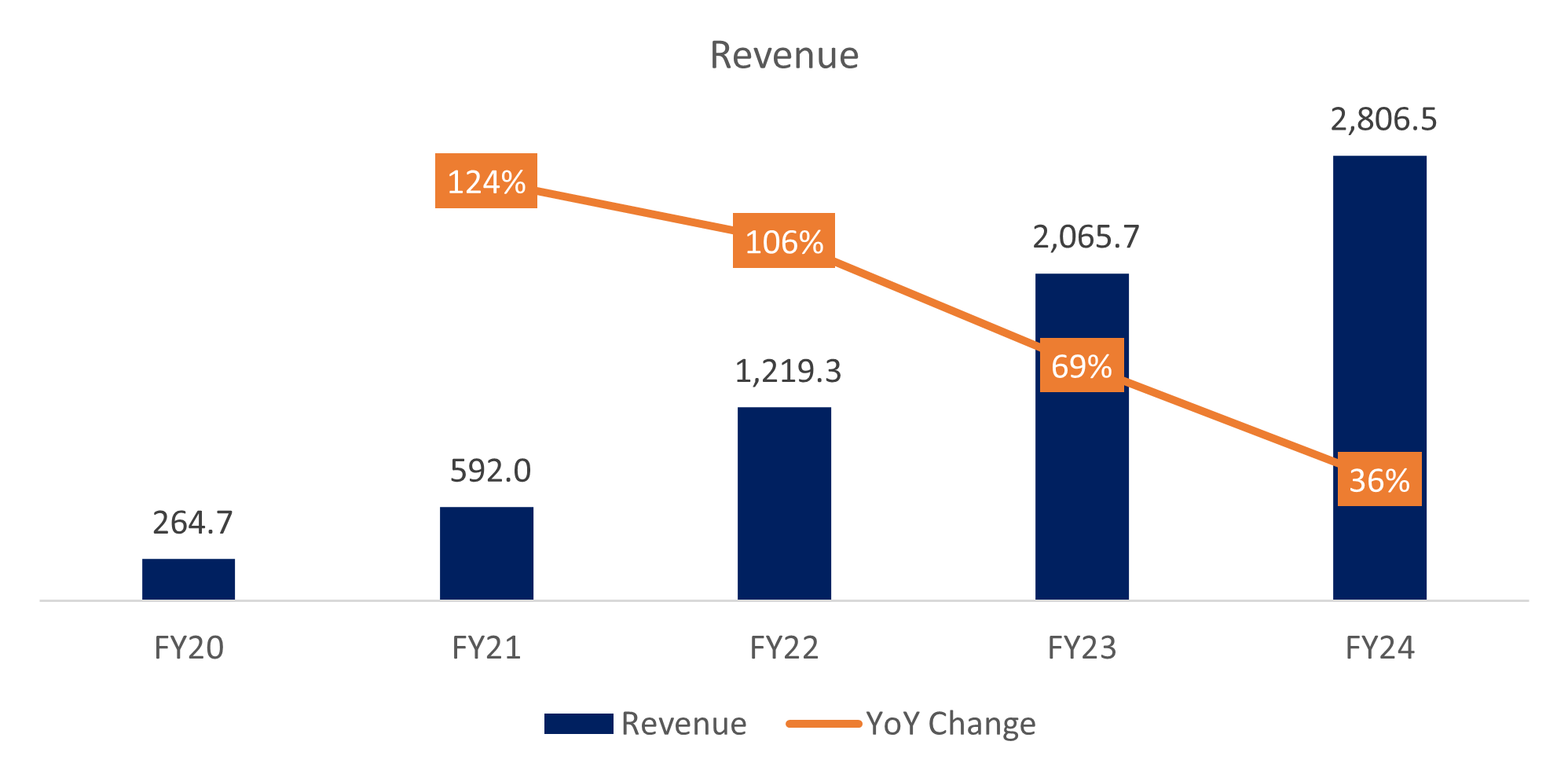
Gross profit margins have trended upwards as Snowflake scaled and negotiated better terms with the hyperscalers.

Contract & Billing Terms
Customers typically enter into 1-to-4-year capacity arrangements or consume under on-demand arrangements, which Snowflake charges monthly in arrears.
More than 95% of revenue is derived from annual or multi-year capacity agreements. Consumption typically ramps after initial implementation to the end of their contract terms as use cases expand more broadly across business units and as additional ones are adopted.
The bulk of this cash is actually collected upfront, as clients are billed annually in advance. So if a customer consumes more capacity than was agreed in the contract, he will have to top up payments. If less is consumed, Snowflake will only allow the remaining capacity to be rolled over if the customer renews the contract for an equal or larger amount, which means having to make another payment. This is why Snowflake’s cash generation is so strong, payments are collected well in advance.
Pricing
Consumption Model instead of Subscription Model
Pricing for Snowflake compute credits varies based on tiered editions of the platform including standard, enterprise, business critical, or virtual private Snowflake. Customers have access to more service options, lower prices, and a long-term price guarantee if they buy pre-purchased capacity instead of the on-demand option.
Recent Earnings
Slootman mentioned: “The year began against an unsettled macroeconomic backdrop. We witnessed lackluster sentiment and customer hesitation due to a lack of visibility in their businesses. Customers preferred to wait and see versus leaning into longer-term contract expansions. This reversed in the second half of the year, and we started seeing larger multi-year commitments. Q4 was an exceptionally strong bookings quarter, we reported $5.2 billion of remaining performance obligations, representing accelerated year-on-year growth of 41%. Consumption trends have improved since the ending of last year, but have not returned to pre-FY '24 patterns.
We have evolved our forecasting process to be more receptive to recent trends. For that reason, our guidance assumes similar customer behavior to fiscal 2024. We are forecasting increased revenue headwinds associated with product efficiency gains, tiered storage pricing and the expectation that some of our customers will leverage Iceberg Tables for their storage. We are not including potential revenue benefits from these initiatives in our forecast. These changes in our assumptions impact our long-term guidance. Internally, we continue to march towards $10 billion in product revenue. Externally, we will not manage expectations to our previous targets until we have more data.”
CFO also mentioned: “Consumption trends are good right now. But we have so many new products coming to GA (general availability) that we're not going to forecast those until we start seeing a history of consumption. So I do think there's, call it conservatism, I call it prudent guidance, and we'll take it one quarter at a time. The spending environment is actually pretty good with our customers.
I just think a lot of the customers we have now that are ramping on Snowflake, are a lot more disciplined. More mature companies than a lot of the digitally native companies where they had these massive valuations and money being thrown at them that they just spent euphorically. The customers we're bringing on and ramping up today, big telcos and banks kind of stuff, have always been very cost-conscious, and they're going to do things at their pace.”
The market was disappointed by the significant miss in revenue guidance for FY25. Snowflake mentioned that many performance enhancements are being rolled out this year, and they are likely expecting this to be a major headwind. CFO mentioned that these were a 6.3% revenue headwind.
Key Debate: Competitive Dynamics
Snowflake overtook traditional on-premise data warehouse providers like Teradata, Cloudera, IBM, Oracle, and SAP, due to their antiquated solutions that fail to meet modern enterprise requirements for data type integration, secure sharing, and user-friendly access. The CFO clarified that these companies are less of concern as competitors because the shift from on-premise to cloud is inevitable.
Instead, Snowflake sees its real competition as Databricks and the major cloud providers, with Google being notably competitive in pricing as of March 2022. Snowflake frequently collaborates with AWS in sales efforts. However, it's important to note the rapid pace of innovation within this sector, which means that competitive edges are quickly diminished. Consequently, the focus must be on the platform's ability to retain customers.
Key Debate: Snowflake vs Databricks
Originally, these companies were created with distinct objectives in mind. Snowflake set out to offer an intelligent, fully scalable cloud-based data warehouse that supports traditional SQL queries and business analytics. Conversely, Databricks was designed to simplify the process of deploying scalable data science clusters in the cloud, allowing users to effortlessly initiate a Spark cluster for data processing using Python or Scala code within notebooks. These notebooks could then be easily shared with fellow data scientists or the broader community for collaborative projects, thanks to the cloud-based nature of the platform.
While each company has traditionally excelled in their respective areas—Snowflake in business SQL and Databricks in data science—they have both spent recent years enhancing their offerings. Their aim is to create a comprehensive cloud data platform that encompasses data warehousing, processing, and streaming capabilities.
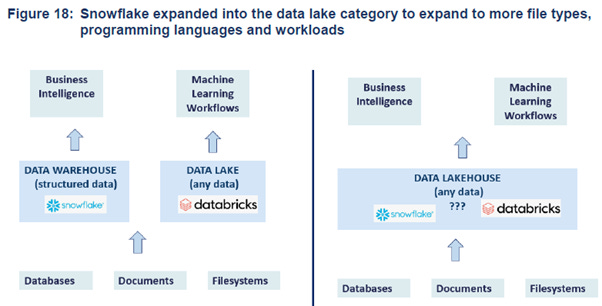
The capabilities between the Snowflake and Databricks increasingly overlap
Snowpark
Snowflake's counterpart to Databricks' offerings is Snowpark, which similarly enables data processing from notebooks in widely-used programming languages. Databricks primarily runs on Spark clusters, or more recently, on Photon clusters, which are an optimized version of Spark written in C++. Similarly, Snowflake operates its own compute engines, also developed in C++. Spark, initially created in Scala—a language known for its relative slowness—benefits from the shift to C++ due to significant performance improvements. Plans are in place to transition the code to Rust, dubbed the new C++, for even further enhancements.
Databricks has expanded its data storage capabilities by integrating with the object storage services of public clouds, allowing for the execution of traditional SQL within its 'Data Lakehouse,' which supports both structured and unstructured data. Both platforms have adopted ACID compliance to ensure consistent, reliable data transactions. Their pricing models are also alike, charging users based on the compute time of virtual machines.
Databricks has evolved into a comprehensive platform, now directly competing with Snowflake. Snowpark is projected to bring in $100 million in revenue for 2024, drawing significant interest for data science projects. In contrast, Databricks' data warehousing solution is expected to generate at least $200 million in revenue for the same period, with a net expansion rate of 140%.
A distinctive feature of Databricks is its separation of the storage layer, utilizing an open-source table format called Delta Tables. This approach allows customers more flexibility in data processing, not limiting them to the Databricks platform. Customers can manage their storage within their chosen cloud service provider, offering a contrast to Snowflake's typically more integrated storage solution.

Databricks Platform Overview
Snowflake is adopting a strategy similar to Databricks by enabling its customers to store data in Apache Iceberg tables, an open-source table format akin to Delta. This move allows customers the flexibility to use their data across different systems, including processing it on Databricks clusters. While this could potentially diminish Snowflake's unique market position, it is seen as a beneficial long-term strategy by making the platform more open and addressing concerns from clients hesitant to commit their data to a closed system.
The transition to cloud-based solutions has been slow for some clients, primarily due to the complexities involved in migration. Snowflake aims to differentiate itself through ease of use, hoping to capture a significant share of the Global 2000 market, even if its compute services might be slower than those of competitors.
A fundamental difference between Snowflake and Databricks lies in their underlying architecture; Snowflake is built on a proprietary system, whereas Databricks leverages an open-source foundation. This difference suggests that Snowflake might be simpler to implement for many organizations, as Databricks' open-source nature could require more technical adjustments. However, the open-source approach of Databricks has the advantage of fostering a strong developer community support.
The choice between Snowflake and Databricks often comes down to specific organizational needs such as security, governance, and ease of use, with Snowflake frequently being the preferred option for those without highly technical staff. This preference is reflected in the choices of some of Snowflake's largest customers, who find Databricks too complex for their needs, indicating the importance of user-friendliness and support infrastructure in technology adoption, especially outside the U.S. where there may be a scarcity of technical talent.
Key Debate: Hyperscalers
The major cloud providers, known as hyperscalers, are also evolving their offerings to stay competitive in the data management and analytics market. AWS Redshift has introduced capabilities for users to store their data in object storage, effectively separating the storage of data from the computational resources. This development is significant as it provides more flexibility and potentially lowers costs for users by allowing them to scale compute and storage independently.
Meanwhile, Google's BigQuery remains one of Snowflake's most formidable competitors in the data warehouse space. However, the cost of using BigQuery, reflective of Google Cloud's overall pricing strategy, is relatively high. This aspect of Google Cloud's service offerings is believed to be a contributing factor to its slower growth rate compared to Azure.
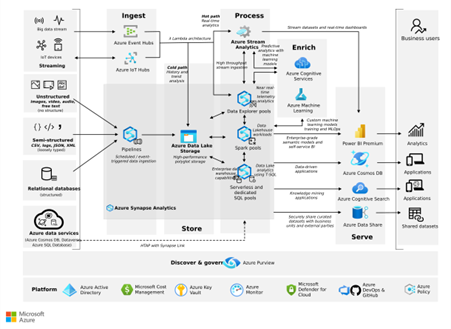
Microsoft data platform on Azure
In the long run, Snowflake could face significant challenges due to the dual role of public clouds as both providers and competitors. There's a potential risk that hyperscalers might adjust their pricing strategies unfavorably for Snowflake, making it more costly for Snowflake to operate on their platforms, while simultaneously offering competitive pricing for their own data services to lure customers. This issue isn't unique to Snowflake; other companies like Databricks, MongoDB, Confluent, and Elastic could encounter similar challenges.
However, such a scenario has not materialized to date. On the contrary, Snowflake has managed to secure more favorable pricing terms from cloud providers, indicating a desire on their part to host Snowflake's services. Despite the competitive landscape where Azure and AWS are perceived to be behind, the leaders in the space include Teradata, Snowflake, Databricks, and Google's BigQuery.
A key advantage for Snowflake is its cloud-agnostic approach, allowing customers the flexibility to choose and combine different cloud services. Snowflake's cloud-native architecture is particularly suited to meet modern business requirements, in contrast to hyperscaler solutions which often originated from an on-premise model and were later adapted for cloud, potentially compromising compute performance. Moreover, data sharing poses less risk on Snowflake, especially for retailers or consumer packaged goods companies wary of sharing data on platforms like AWS, which could be seen as directly competing through Amazon's e-commerce operations.
The relationship between Snowflake and the hyperscalers, particularly AWS and Azure, appears to be more symbiotic than antagonistic. These platforms have formed partnerships with Snowflake to offer combined product portfolios, benefiting from Snowflake's use of their storage and compute resources. Snowflake's growth largely comes from migrating databases from legacy on-premise vendors to the cloud, often directly competing with the hyperscalers for business.
Valuation
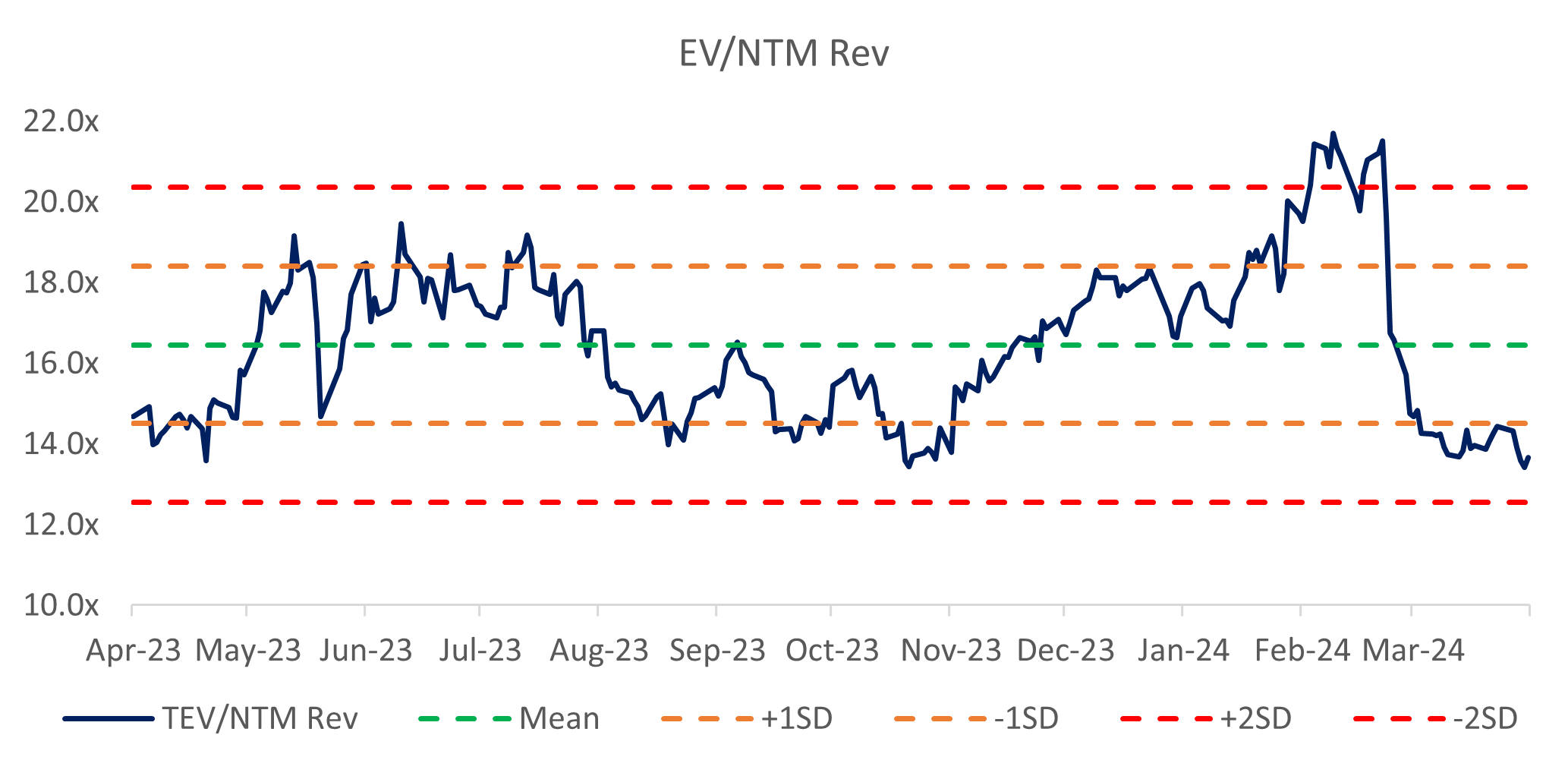
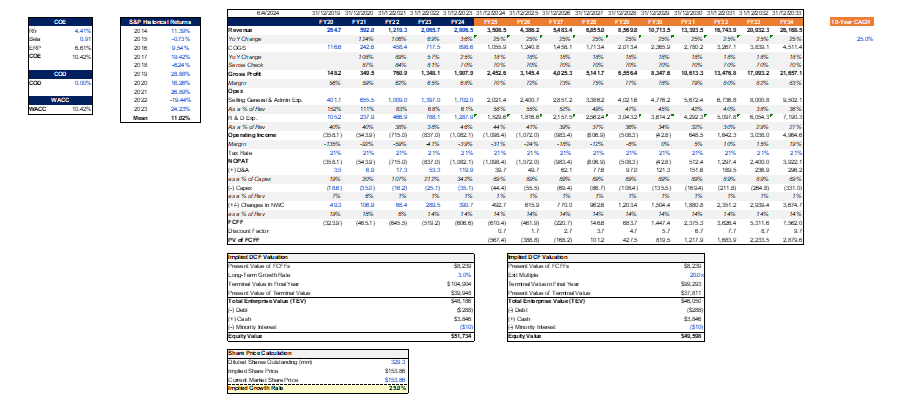
I figured a reverse DCF was more apt to sense check whether the valuation was attractive enough to initiate a position in the company. According to my assumptions, a 25% 10-year revenue CAGR would be required to justify the current valuation, and I believe that is still too risky for me, and a ballpark range of around 20% would be more acceptable to me (implying a target price of around $100).
I expect to re-evaluate the company again further down the line.
Disclosure: I do not own this stock.